在我们日常浏览百度或者其他搜索引擎搜索相关内容时,会有一些链接打开后与实际索引的标题描述不符,也可能和收录的内容完全不同,那么这是怎么做到的呢?
首先需要知道的是百度搜索的工作原理。
爬取网页:百度搜索引擎通过爬虫程序自动抓取互联网上的网页,并将这些网页中的信息和内容保存在搜索引擎的数据库中。
建立索引:百度搜索引擎对每个网页进行分词处理,将网页中的关键词和内容与相应的索引关键词建立联系,建立索引,以便后续的搜索能够快速地定位到相关网页。
排序:当用户输入查询关键词时,百度搜索引擎会将查询关键词与已建立的索引进行匹配,并根据关键词的相关性、网页的权重、链接数量等多个因素对搜索结果进行排序,以便返回最相关、最有价值的结果给用户。
返回结果:百度搜索引擎将搜索结果返回给用户,用户可以通过搜索引擎页面查看搜索结果,并进行相关的操作,如访问网页、搜索相关内容等。
需要注意的是,百度搜索引擎还会根据用户的搜索历史、地理位置、设备类型等多个因素对搜索结果进行个性化定制,以提供更符合用户需求的搜索结果。
下面我们来分析一下为什么展示的页面会和索引内容不同?
蜘蛛爬取的页面和展示的页面不一样的主要好处是可以优化网站的性能和用户体验。具体而言,这种技术可以使搜索引擎能够更快地爬取网站内容,同时在展示给用户时也能够更快地加载页面。这对于提高网站的搜索引擎排名和用户留存率都有积极的影响。
这种技术也可以通过隐藏某些内容来保护版权和隐私。例如,一些网站可能会在爬取页面时去掉一些敏感信息,如电话号码、电子邮件地址等,以防止被不良机构或个人滥用这些信息。
这种技术并不能完全规避侵权问题。如果某些网站在展示给用户的页面中侵犯了他人的版权或隐私权,那么他们仍然会面临法律责任。因此,网站运营者应该始终确保他们的网站内容不侵犯他人的权益,并采取适当的措施来保护用户的隐私和个人信息。
同样也会有通过这一机制来把真是展现的内容伪装成其他内容。
下面我们来看看具体一点的。
我们通过百度来搜索:奶茶加盟网
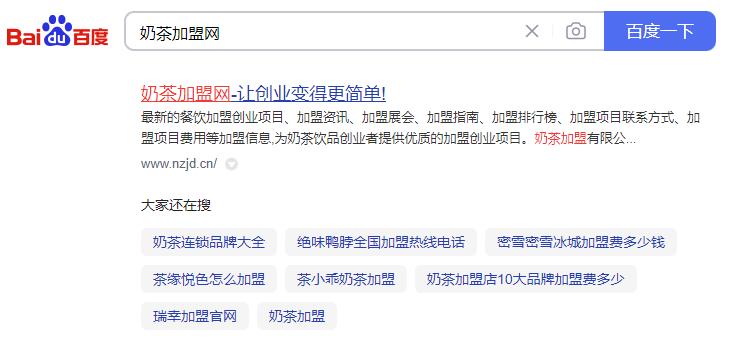
点击链接打开是一个类似于SEM页面的内容。
我们接着用Python来模拟爬虫爬取一下页面。

文章就写到这里,感兴趣的读者可以深入研究一下你会发现更多惊喜。